Here’s something that’ll blow your mind: the way fintech companies decide whether to lend you money is getting a serious upgrade. And I’m not talking about minor tweaks to old formulas — I’m talking about reinforcement learning algorithms that literally learn from every lending decision they make.
Prefect vs Airflow for ML Pipelines: Which Workflow Tool to Choose?
on
Get link
Facebook
X
Pinterest
Email
Other Apps
Your ML pipeline has grown from a single training script to a complex workflow — data ingestion, preprocessing, feature engineering, training, evaluation, and deployment. You’re managing dependencies with cron jobs and bash scripts held together with hope and duct tape. When something fails, you have no idea what broke or how to restart from the failure point. You know you need an orchestration tool, but everyone recommends different things.
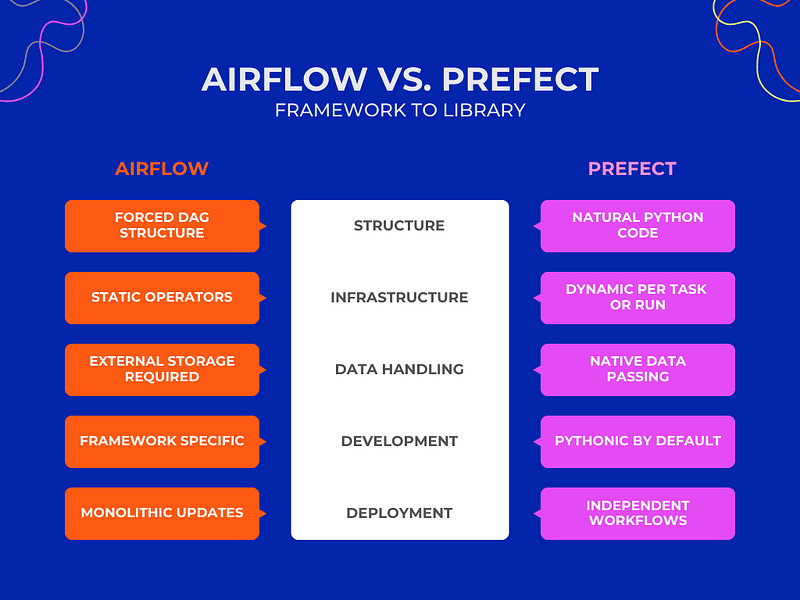
I’ve used both Airflow and Prefect extensively for ML pipelines. Airflow at a company with 100+ data scientists, Prefect on personal projects and smaller teams. They solve the same problem — workflow orchestration — but approach it completely differently. Airflow is the established enterprise tool with every feature imaginable and all the complexity that implies. Prefect is the modern alternative that’s actually pleasant to use. Let me break down which one you actually need.
Prefect vs Airflow for ML Pipelines
The Core Difference (Philosophy Matters)
Before comparing features, understand the fundamental philosophical difference:
Airflow feels like a job scheduler with Python integration. Prefect feels like Python with orchestration capabilities. This difference permeates everything else.
Database backends (SQLite for dev, Postgres/MySQL for prod)
Multiple services (webserver, scheduler, workers)
Prefect Setup (Simple)
bash
# Install Prefect pip install prefect
# Optional: Start local server prefect server start
# Or use Prefect Cloud (free tier) prefect cloud login
That’s it. Prefect works locally without any setup. The server is optional for UI/monitoring.
Winner: Prefect. Setup time: 2 minutes vs. 30 minutes.
Defining Workflows
Airflow DAGs (Configuration-Heavy)
python
# airflow_dag.py from datetime import datetime, timedelta from airflow import DAG from airflow.operators.python import PythonOperator
# DAG must be defined at module level default_args = { 'owner': 'data-team', 'depends_on_past': False, 'start_date': datetime(2024, 1, 1), 'email': ['alerts@example.com'], 'email_on_failure': True, 'email_on_retry': False, 'retries': 3, 'retry_delay': timedelta(minutes=5), }
dag = DAG( 'ml_training_pipeline', default_args=default_args, description='ML training workflow', schedule_interval='0 0 * * *', # Daily at midnight catchup=False )
def load_data(**context): """Load data from source.""" # Your logic here return data_path
def preprocess(**context): """Preprocess data.""" # Get output from previous task data_path = context['task_instance'].xcom_pull(task_ids='load_data') # Your logic here return processed_path
def train_model(**context): """Train model.""" processed_path = context['task_instance'].xcom_pull(task_ids='preprocess') # Your logic here return model_path
# Or with custom retry logic from prefect import task from prefect.tasks import task_input_hash from datetime import timedelta
@task( retries=3, retry_delay_seconds=60, cache_key_fn=task_input_hash, cache_expiration=timedelta(hours=1) ) def expensive_computation(data): # Won't recompute if called with same input within 1 hour pass
Prefect adds caching on top of retries — smart for expensive ML operations.
Winner: Prefect. Retries plus intelligent caching.
Monitoring and Observability
Airflow UI
Pros:
Comprehensive DAG view
Task duration metrics
Gantt charts
Log viewing
Historical runs
Cons:
Complex interface
Slow on large installations
Hard to customize
Prefect UI
Pros:
Clean, modern interface
Real-time updates
Flow run radar
Simple navigation
Customizable dashboards (Prefect Cloud)
Cons:
Less mature than Airflow’s UI
Fewer built-in visualizations
Winner: Tie. Airflow’s UI is feature-rich but cluttered. Prefect’s is cleaner but less comprehensive.
For new ML projects: Start with Prefect. It’s simpler, more Pythonic, and you can actually run/test workflows locally. The learning curve is gentle, and you’ll be productive immediately.
For existing Airflow shops: Stick with Airflow unless pain points are severe. Migration isn’t worth it if Airflow works for you.
For complex data engineering: Airflow’s maturity and ecosystem still edge out Prefect for very complex data pipelines with many integrations.
For ML-specific pipelines: Prefect. The code-first approach, caching, and local development align better with ML workflows.
IMO, if I were starting a new ML platform today, I’d choose Prefect without hesitation. Airflow feels like legacy infrastructure comparatively. But Airflow’s not going anywhere — it’s still the dominant player and has years of polish. The question is whether you value Prefect’s modern simplicity over Airflow’s maturity and ecosystem.
Migration and Interop
Can’t decide? Use both:
python
# Call Airflow DAG from Prefect from prefect import task import requests
Airflow and Prefect solve the same problem but appeal to different sensibilities. Airflow is the established enterprise standard with every feature and all the complexity. Prefect is the modern alternative that’s actually pleasant to use.
Choose Prefect if: You want modern Python-first orchestration that’s easy to learn and use.
For ML pipelines specifically, Prefect’s code-first approach, local execution, and caching make it the better choice for most teams. But Airflow’s maturity means it’s not going anywhere, and large organizations have good reasons to stick with it.
Installation:
bash
# Airflow (complex) pip install apache-airflow
# Prefect (simple) pip install prefect
Stop agonizing over the choice. If you’re starting fresh, try Prefect for a week. If it doesn’t click, Airflow will still be there. But you’ll probably find that Prefect’s simplicity wins. :)
Loving the article? ☕ If you’d like to help me keep writing stories like this, consider supporting me on Buy Me a Coffee: https://buymeacoffee.com/samaustin. Even a small contribution means a lot!

Comments
Post a Comment